Microservices Architecture Principles
Microservices Architecture Principles
What is a microservices architecture
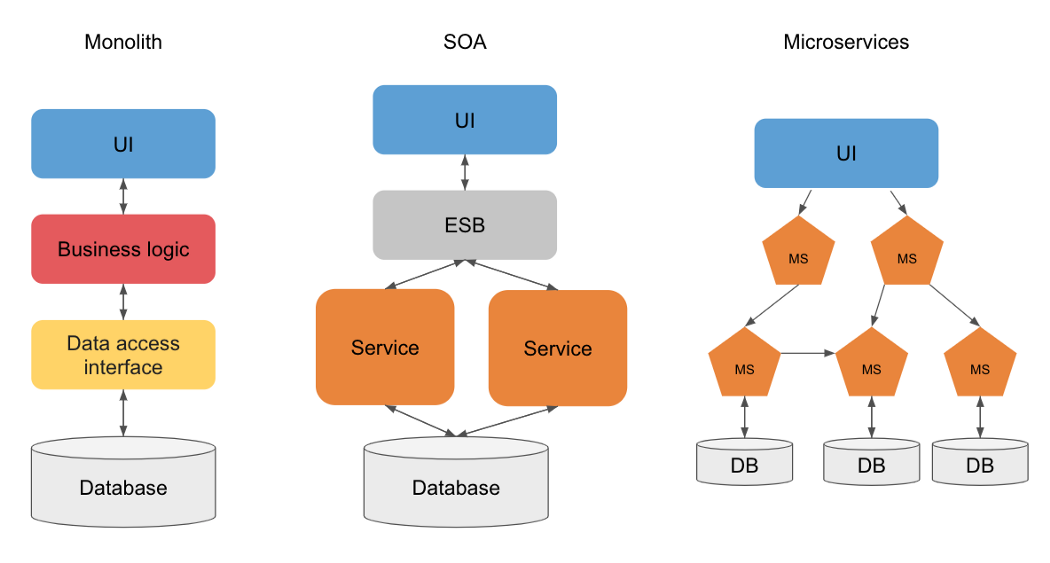
Essentially, microservices architecture is a method of software development that aims to break down an application to isolate key functions, each of these functions is called a “service”. These services are designed to meet a specific and unique business need, for example: user management, payments, sending emails or even notifications. In addition, they are independent and modular, this allows each to be developed and deployed without affecting the others. This type of architecture is intended to be the opposite of monolithic architectures which are built as a single autonomous unit.
This definition may recall another type of architecture quite similar, Service Oriented Architecture (SOA), a software design already well stated.
What makes an SOA architecture different from a microservices architecture?
Let’s start with a clear observation, made by the precursors of microservices: this architecture is an extension of the concept of SOA. Most of the design principles for microservices were already available in the SOA world. Some people claim that “the microservices architecture is a well-designed SOA architecture.” Let’s see the differences between SOA and microservices along several axes:
Size: One of the big differences is the size and scope of services. As you can guess from the name, in microservices, the size of each service is much smaller than the one of SOA services. In a microservices architecture, each service has a single responsibility while in the SOA architecture, services can contain many business functions.
Reusability: One of the goals of SOA is to reuse components without worrying about coupling while in microservices we try to minimize reuse since this creates dependencies that reduce agility and resiliency. A weak coupling is preferred, even if it means having code duplication.
Communication: In SOA, communication between services is usually done synchronously through an enterprise service bus (ESB), this introduces a critical point of failure and latency. In a microservices application, fault tolerance is better thanks to the independence of each service, asynchronous communication is also privileged between services (for example a publish subscribe model can be used to allow a service to stay up to date on changes to another one’s data), enabling high availability.
Data duplication: One of the goals of an SOA is to allow all applications to access data synchronously directly at the source. With a microservices architecture, each service has access to all the data it needs locally (ideally) to have maximum performance and agility, even if this means having to duplicate data and therefore add complexity.
Let’s sum it all up with a diagram:
Advantages and disadvantages of a microservices architecture
Now that we have a better understanding of what a microservices architecture is, let’s see what are the advantages and disadvantages of it compared to a monolith architecture. We’ve seen a number of benefits before, but let’s go over them all:
Advantages
Independent Development: Teams can choose the technologies that best suit each service using various technology stacks and are not limited by the choices made at the start of the project. Additionally, a single development team can build, test, and deploy a service, enabling faster deployment and facilitating continuous innovation. It is also more difficult to make mistakes since there are strong boundaries between the different services.
Independent deployment: Microservices are deployed independently. A service can be updated without having to redeploy the entire application, making it easier to manage bug fixes and new features. This simplifies integration and continuous deployment. In many traditional applications, if there is a bug in one part of the application, it can block the entire release process.
Independent scaling: Services can scale independently to suit needs, optimizing costs and time since there is no need to scale the entire application as you would with a monolith.
Small Targeted Teams: Teams can be targeted to only one service, making code easier to understand and making it easier for new members to join the team, no need to spend weeks figuring out how a complex monolith works. It also promotes flexibility, large teams tend to be less productive because communication is slower, management time increases and agility decreases.
Small Code Base: In a monolithic application, code dependencies tend to get mixed up over time. Adding new functionality requires changing the code in a lot of places. In a microservices architecture, which does not share code or database, these dependencies are minimized, which makes it easier to add new features. It also complements the previous point that it makes it easier to understand the code and introduce new members to the team.
Data isolation: In a microservices architecture, each service has private access to its database (ideally), we can then perform an update of the database schema without affecting the other services. In a monolithic application, schema updates can become very difficult and risky since multiple parts of the application can use the same data.
Resilience: With a microservices architecture, critical points of failure are considerably reduced. When a service goes down, the whole application does not stop functioning as it does with the monolithic model and therefore the risk is also reduced when new features are developed. Errors are also isolated and therefore easier to correct.
Technological Advances: Recent advancements in cloud technologies and containerization make setting up a microservices architecture increasingly simple. Every cloud provider has solutions for this type of architecture to make life easier for developers.
Disadvantages
Now that we have a better idea of all the advantages of a microservices architecture, let’s see what the disadvantages and challenges are:
Complexity: While each service is simpler, the system as a whole is more complex. Because this is a distributed system, care should be taken to select and set up all services and databases, and then deploy each of these components independently. All the challenges of a distributed system must be taken into account.
Testing: Having multitude independent services can make writing tests more complex, especially when there are many dependencies between services. A mock must be used for each dependent service to be able to unit test a service.
Data Integrity: Microservices have a distributed database architecture, which is a challenge for data integrity. Some business transactions, which require updating multiple business functions of the application, need to update multiple databases owned by different services. This requires setting up eventual consistency of data, which is obviously more complex and less intuitive for developers.
Network latency: Using many small services can result in increased communications between services. Also, if you have a chain of dependency between services to perform a business transaction, the additional latency that results can become a problem. Asynchronous communications should be favored when usage permits, but this once again adds complexity to the system.
According to these advantages and disadvantages it is then more or less relevant to adopt a microservices architecture, there is no universal rule, each project is unique and the motivations towards one architecture or the other depend on the needs and the context of it.
Orchestration vs Choreography
In a microservices architecture, it is inevitable that some services need to communicate with each other, these communications can be achieved in two ways, orchestration or choreography. A lot of documentation exists on these two models, including a publication by Chaitanya Rudrabhatla in the International Journal of Advanced Computer Science and Applications (IJACSA), executive director and architect at Sony Pictures Entertainment.
Orchestration
The first intuitive idea to make the services communicate with each other is quite simply to make REST calls between the services:
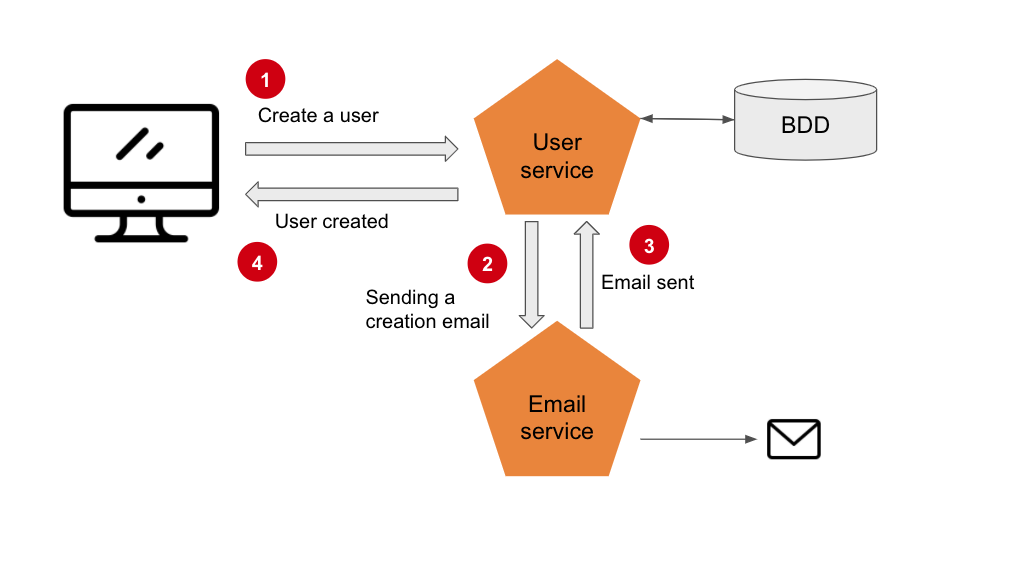
This approach is simple to set up but the system quickly becomes complex to maintain since we introduce dependencies between services, which we want to avoid as much as possible. A more thoughtful way to do this transaction is to introduce an additional abstraction with a new service, an orchestrator:
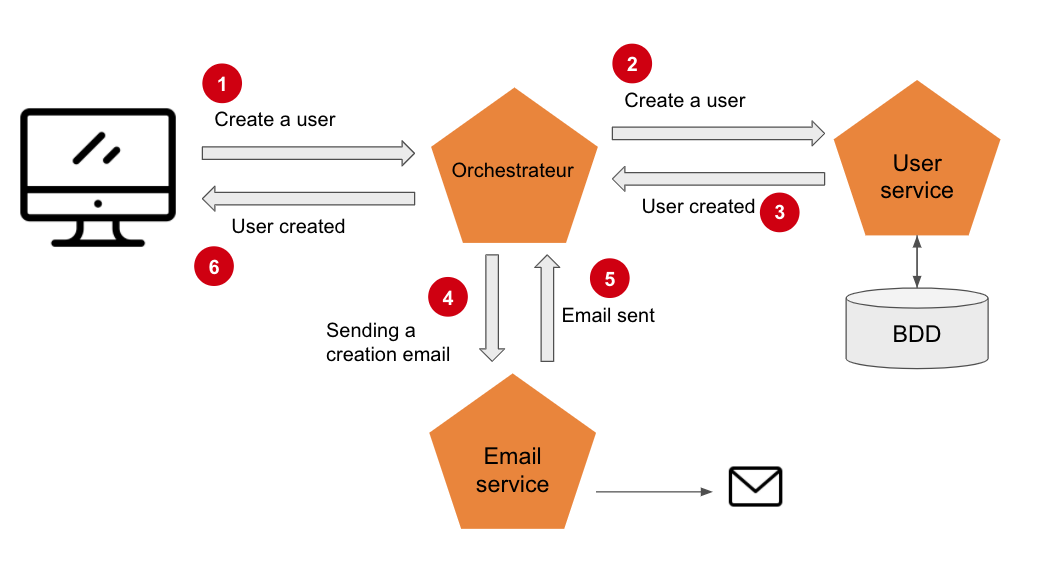
The orchestrator is the only one to have knowledge of the other services, in case of an update of the services, it will still be necessary to be careful not to “break” the orchestrator, but we have the advantage that it is the only one affected by the changes. However, with this approach or the previous one, there are still drawbacks which are the latency this can introduce due to synchronous calls, and poor fault tolerance. Also on a system made up of a large amount of services, one can quickly come up with a system with a lot of dependencies that looks like a distributed monolith. Orchestration should therefore be used sparingly.
Choreography
The choreography overcomes the various disadvantages of orchestration, there is no dependency or latency in the system. The solution is to use events with a publish-subscribe model:
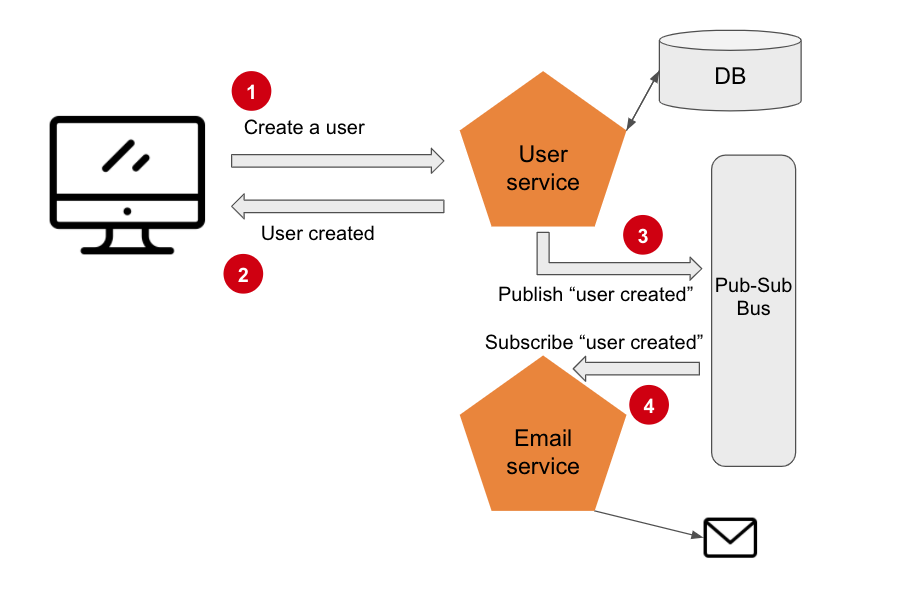
When an action is taken, the service in question will publish an event to which the other services will be able to subscribe to make the necessary changes. Communication is asynchronous and services are unaware of each other, therefore the system is efficient and easy to maintain on a large scale. In the event of a service failure, the system continues to operate, but the consistency of the data can be lost, the high availability of the system is favored, in cases where the consistency of the data is critical, it is completely possible to set up circuit breakers to automatically deactivate certain services.
Advice and good practices
The following tips and best practices are largely inspired by Michael Bryzek, co-founder and CTO at Flow.io, and his talk “Design microservice architectures the right way”, I truly recommend everyone to watch this video.
Microservices languages
We saw previously that one of the advantages of a microservices architecture is that each service can be developed with the language you want. In practice, it is advisable to limit the number of languages used as much as possible. This allows developers to easily switch teams and work on any service and be productive very quickly, even more if there is strong consistency between services. By limiting the number of languages, recruiting is also simplified.
API definition
An architecture driven by its specifications is the best way to produce quality APIs. API definitions can be made in JSON or YAML independently of the code (not generated with annotations) so as not to be dependent on the languages used in the services. All placed in a separate project that brings together all the specifications in order to have a single place to manage the specifications. It is then possible to set up a linter on this project to guarantee the consistency of style of all the APIs. In the definition of APIs, it is wise to provide a route to know the state of the service (example: “/health”) and also to provide for API versioning so as never to “break” anything for the users who use it.
Code generation
Thanks to a good definition of APIs, it is possible to generate code to create all the services. In this way we are certain that the definition really corresponds to what the services expose (the generated code must obviously not be modified, but must expose interfaces allowing to implement the necessary methods) and we also ensure a strong consistency. This avoids wasting time with repetitive tasks that have no added value. In this generation of code, you also have to plan for the generation of the necessary tests and mocks, it is important to think about this from the start to avoid it becoming very complex.
Databases
Each service has its own database that no other service can access. If this very important rule is lost, database updates become risky and complex since fixes must be made in all the services that access this database. If a service needs to make changes based on another service, it must go through its API or through events.
Continuous deployment
Continuous deployment is a prerequisite for managing a microservices architecture. Without continuous deployment, each service would have to be deployed by hand, which would be time consuming, error prone, and significantly slow down the time between each update.
Services communication
To allow communication between services, it is better to use event streams rather than using REST requests on APIs, only use APIs in case there is no other choice than to do a synchronous transaction. Using events with a publish-subscribe model reduces latency for users (since communication is asynchronous), and in the event of an error, it is possible to replay a chain of events if they were recorded in a newspaper. In addition, you can trace everything that has happened in the system easily. As with APIs, it is important to maintain an event schema specification that all developers can trust. Lastly, each event producer must have at least one recipient and each consumer must be idempotent.
Maintenance of dependencies
Maintaining a microservices architecture can be a challenge. Each service has dependencies that need to be updated while ensuring that the service continues to function properly. Depending on the number of architectural departments, this task can take a long time. Fortunately, this process can be automated with a script that runs every week (for example), and with the testing in place, we can ensure that the architecture continues to function.